

1. 딥시 R1이란?
딥시 R1은 최근 주목받고 있는 AI 모델로, GPT-4급 성능을 목표로 하는 오픈 소스 대형 언어 모델(LLM)이다.
오픈AI의 GPT-4와 비교하여 학습 비용이 10분의 1 이하로 적게 들었으며, 일부 벤치마크에서 더 나은 성능을 보였다. 모델의 가중치(Weights)를 공개하고 상업적으로도 자유롭게 활용할 수 있게 제공하는 것이 강점.
2. 기존의 AI 학습 방식과 딥시 R1의 차별점
💡 기존 LLM 학습 방식
프리트레인 모델 → SFT(지도학습) → 리워드 모델링 → RLHF(PPO)
OpenAI의 ChatGPT, 메타의 Llama 2 등도 이 방식 사용
RLHF(강화학습) 방식은 컴퓨팅 자원이 많이 필요하고 수렴이 어려움
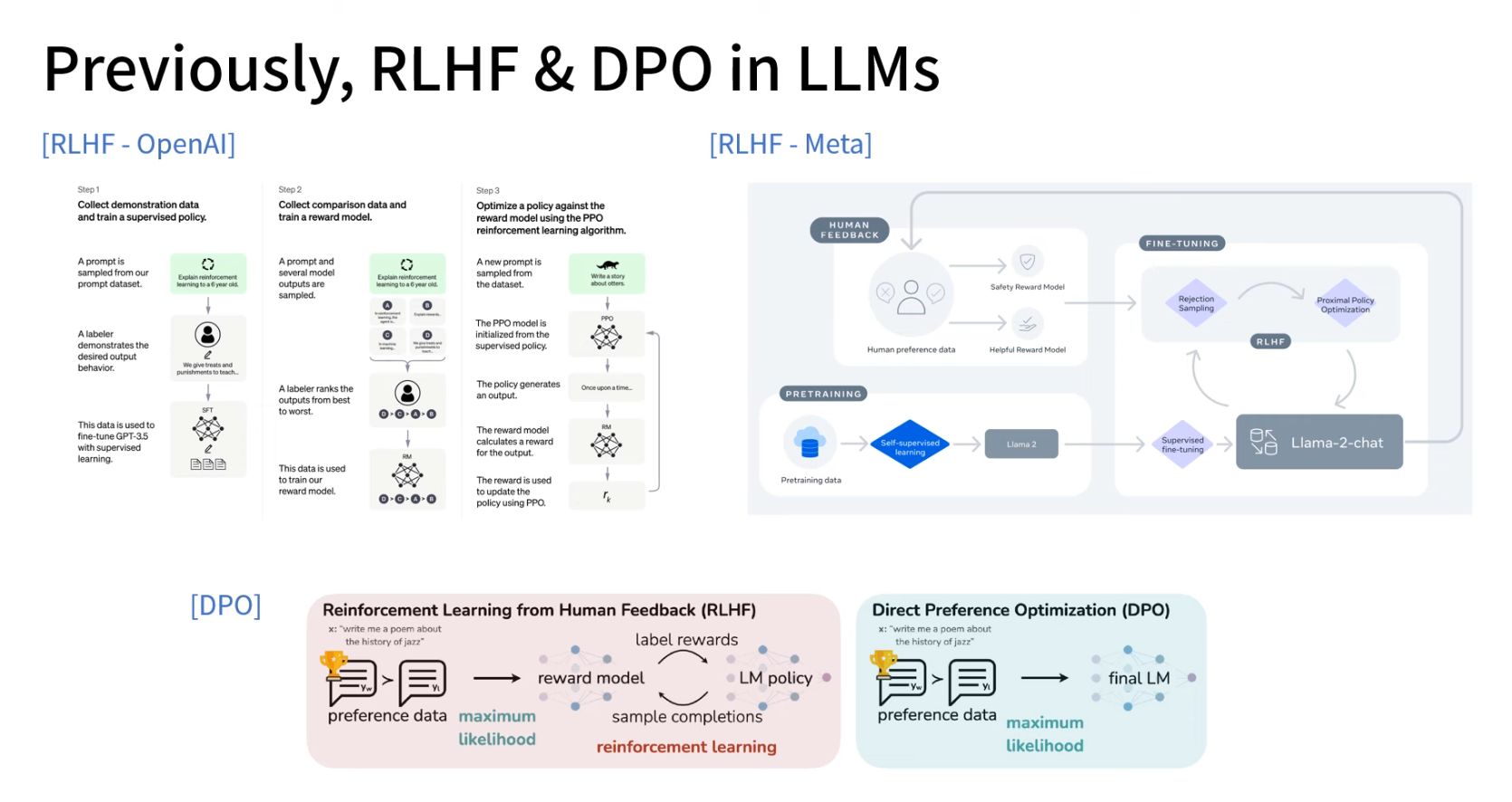
💡 딥시 R1 학습 방식
기존 방식의 비효율성을 극복하기 위해 DPO(Direct Preference Optimization) 방식 활용
DPO는 리워드 모델 없이 직접 선호 데이터를 학습하여 더 안정적
Llama 3에서도 RHF(강화학습) 대신 DPO 방식으로 학습

3. 딥시 R1의 학습 과정
📌 기본 모델 - 딥시 V3
딥시 V3는 GPT-4급 AI로, 딥시 R1의 기반 모델
H800 GPU 클러스터(미국의 GPU 수출 규제 문제)로 학습
프리트레이닝 데이터: 14.8조(Trillion) 개의 토큰 사용 (Llama 3와 유사)
학습 비용은 약 80억 원
수학, 코딩, 논리적 추론(Reasoning) 데이터를 대량 학습
📌 딥시 R1 0 (R1 Zero) - RL 기반 학습 실험
지도학습(SFT) 없이 강화학습(RL)만으로 학습한 실험 모델
수학과 코딩 문제에서 높은 성능을 보였으나 언어적 표현이 매끄럽지 않음
GPT-3.5가 RLHF에 3만 개 데이터를 쓴 것처럼, R1 Zero도 몇 만~수십만 개의 리즈닝 데이터로 학습
📌 딥시 R1 (정식 버전) - 개선된 학습 과정
R1 Zero의 부족한 점을 보완하기 위해 4단계 학습 진행
1️⃣ 콜드스타트 데이터 학습 → R1 Zero의 답변을 정제해 SFT 진행
2️⃣ RL 학습 진행 → GRP(Gradient Reward Prediction) 방식 사용
3️⃣ SFT 재학습 (80만 개 데이터 활용) → GPT-4 수준의 데이터 세트 사용
4️⃣ 최종 RL 학습 진행 → 리즈닝과 일반적인 답변 능력 강화
4. 딥시 R1의 주요 기술적 특징
📌 MOE (Mixture of Experts) 아키텍처
기존 모델보다 257개의 전문가 레이어를 활용하여 성능 최적화
2048 사이즈의 전문가 네트워크 중 8개를 선택하여 효율적인 연산 수행
📌 MLA (Multi-Layer Attention) 기법
기존의 MQA(GQA)보다 더 나은 성능을 유지하면서도 메모리 사용량 절감
모델 성능을 저하시키지 않고 메모리 효율성을 극대화
📌 MTP (Multiple Token Prediction)
기존 LLM이 1개씩 예측하던 것을 2개 이상 동시에 예측하도록 학습, 학습 속도 개선 및 성능 향상
📌 Fill-in-the-Middle 로스 (FIM Loss) 적용
기존 모델들은 좌 → 우 방향으로만 학습했지만, 딥시 V3는 **중간 구멍을 메우는 방식(FIM)**으로 학습
긴 문맥 내에서 중요한 정보를 잃어버리는 현상(Lost-in-the-Middle) 해결
5. 딥시 R1의 성능 평가
📌 GPT-4, Claude 3.5 등과 비교한 성능
일반적인 질문 및 추론(Reasoning) 성능에서 GPT-4급의 결과
수학, 코딩 벤치마크에서 GPT-4 및 Claude 3.5보다 우수한 결과
긴 문맥을 다룰 때 성능 유지력이 강함 (Lost-in-the-Middle 문제 해결)
📌 중요한 발견: AI가 스스로 더 깊은 사고를 학습
AI가 학습 과정에서 Think(Think) 태그 안에 더 많은 내용을 작성하며 깊은 사고를 스스로 강화
“아하 모멘트(Aha Moment)”라는 현상 관찰됨 → AI가 스스로 문제 해결 방식 개선
📌 딥시 R1의 단점
영어와 중국어를 혼합하는 문제
복잡한 함수 호출 및 멀티턴 대화가 다소 약함
기존 RLHF 모델과 달리 퓨 샷(Few-Shot) 학습보다는 제로 샷(Zero-Shot) 학습에서 더 나은 성능을 보임
6. 딥시 R1의 의미와 미래 전망
📌 오픈소스 AI 혁신
기존 대형 모델들은 OpenAI나 Google이 주도했지만, 딥시 R1은 오픈소스로 제공됨
학습 비용을 크게 줄이고도 GPT-4급 성능을 달성
📌 "Phase 2 AI" 시대의 시작
샘 알트만(OpenAI CEO)이 언급한 추론(Reasoning) 중심의 AI 시대가 본격적으로 시작
단순한 언어 생성이 아니라 논리적 사고와 문제 해결 능력을 강화하는 모델이 트렌드가 될 것
📌 딥시 R1의 향후 연구 방향
펑션 콜, 멀티턴 대화 성능 개선
랭귀지 믹싱 문제 해결
제로샷 최적화 방식 개발
📌 결론: 딥시 R1은 GPT-4급 오픈소스 AI의 시작점
1️⃣ 학습 비용이 10배 이상 절감되면서도 GPT-4급 성능을 달성
2️⃣ 순수한 RL 학습만으로도 강력한 AI 모델을 구현
3️⃣ 스스로 깊은 사고를 학습하는 AI 구조를 적용
4️⃣ 오픈소스 생태계를 확장하며 AI 연구의 민주화 촉진